Object detection or recognition is one of the key challenges in computer vision with a wide range of applications including industrial automation, security systems, autonomous vehicles and medical diagnostics. Current methods for this task are based on deep learning, which can significantly improve the accuracy and efficiency of image processing.
Neural network-based recognition methods are widely used in machine learning models. For this purpose, a training database is collected, from which a dataset is formed. Features and their combinations are extracted to identify similar objects. The machine learning model is trained to recognise the right types of patterns. Even after loading several datasets, the model may not recognise some objects correctly. If this happens, the model continues to be trained on new datasets until it reaches the desired detection accuracy. In addition, neural networks are extremely demanding to the size and quality of the dataset that will be presented as a training sample. The number of examples in this sample can reach tens and hundreds of thousands, and all of them must be prepared for training, which is a labour-intensive task. Therefore, there are a lot of open prepared datasets. However, they are more often used as test cases of network performance, because a specific dataset is required for a particular application task.
In practice, this means that up to a certain limit, the more hidden layers in the neural network, the more accurately the image will be recognised, and this number is increased until the onset of overtraining [1]. The input of the neural network is a picture, which is divided into small areas, up to several pixels, each of which will be an input neuron. During this process, hundreds of thousands of neurons with millions of weight coefficients compare the received signals with already processed data and make adjustments to the weight values.
Object detection methods are typically based on either machine learning or deep learning. Methods based on deep learning are characterised by the use of convolutional neural networks, which enable object detection without using a list of specific features of a given object [1].
There are many different approaches and architectures of neural networks, each with its own advantages and disadvantages:
– Region Proposals (с использованием различных региональных сверточных нейронных сетей: R-CNN, Fast R-CNN, Faster R-CNN) [2]:
- Single-Shot MultiBox Detector;
- You Only Look Once (YOLO);
– RetinaNet;
- Single-Shot Refinement Neural Network for Object Detection (RefineDet);
– Deformable convolutional networks.
One of the best known families of models for object detection is R-CNN, which includes variations such as Fast R-CNN and Faster R-CNN. These models use a region-based approach that can efficiently extract objects in an image and classify them. Another popular architecture is YOLO (You Only Look Once), which is characterised by high speed performance due to viewing the image once and classifying and localising objects simultaneously. Each of these models has unique characteristics, making their selection critical to successfully solving a particular object detection problem. Let’s take a closer look at these two architectures and analyse them comparatively.
The R-CNN or regional convolutional neural network model is a selective search method, is an alternative to full image search for fixing the location of an object [3]. It combines small regions of an image into a hierarchical group. Thus, the last group is a block containing the entire image. The model starts by searching the region and then performs classification. Thus, the last group represents a block containing the entire image. The detected regions are combined according to different colour spaces and similarity scores. The result is a number of region suggestions that may contain the object.
The size of each region suggestion is resized to match the input from the CNN (convolutional neural network) from which a feature vector is extracted [2]. The feature vector is classified to obtain the probabilities of belonging to each class. Each class has an SVM classifier that uses the support vector methods [4], inferring the detection probability of that object for a given feature vector. This vector also feeds a linear regressor to adapt the shapes of the bounding box to suggest the region and thus reduce localisation errors.
Each region sentence feeds a CNN to extract a feature vector, possible objects are detected using multiple SVM classifiers, and a linear regressor modifies the coordinates of the bounding box.
The disadvantages of R-CNN include:
— training the network takes a huge amount of time, we have to classify several thousand region sentences for each image;
— cannot be used in real time, it takes about 50 seconds for each test image;
— the sampling search algorithm is a fixed algorithm, so there is no training for it, this may lead to the creation of bad candidate region suggestions.
The goal of the Fast R-CNN region-based convolutional network Fast R-CNN is to reduce the time cost associated with the large number of models required to analyse all region proposals.
A basic CNN with multiple convolutional layers processes the whole image as input, in contrast to the R-CNN approach where the CNN is applied separately to each region proposal [4]. The regions of interest are identified by a sampling method which is applied to the generated feature maps. Each region of interest is then fed into fully connected layers that form a feature vector. This vector is used to predict the object class using a softmax classifier, a normalised exponential function that converts a vector of real numbers into a probability distribution of possible classes, and to refine the coordinates of the bounding box through a linear regressor.
The Faster R CNN is an improved version of the R CNN (Regions with CNN features) introduced in 2015. This architecture addresses the original R CNN’s problems of slow speed and high resource consumption by introducing the Region Proposal Network (RPN). The Region Proposal Network, otherwise Region Proposal Network or RPN (see Fig. 2.1) for direct region proposal generation presents bounding box prediction and object detection. RPN uses a pre-trained ImageNet dataset model for classification and fine-tunes the PASCAL VOC dataset [3]. A faster region-based convolutional network Faster R-CNN is a combination between RPN and the Fast R-CNN model.
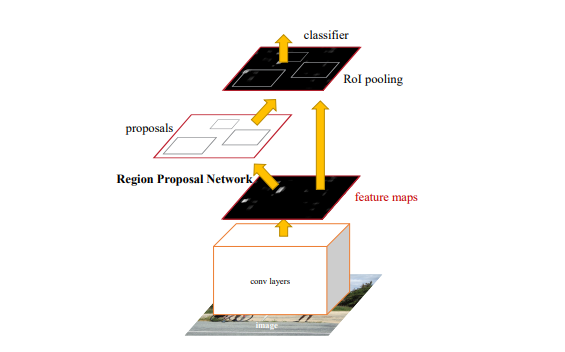
Figure 1. Region proposal network
In this case, the CNN takes the entire image as input and creates feature maps. The defining window slides over all feature maps and outputs the feature vector associated with two fully connected layers, one for block regression and one for block classification. Suggestions of multiple regions are predicted by the fully connected layers. If k regions are detected, the output of block regression layer is of size 4*k, the coordinates of the blocks, their height and width, and the output of block classification layer is of size 2*k to detect the object or not in the region. The region suggestions detected by the sliding window are called anchors. When anchors are detected, they are selected by applying a threshold to the objectivity score to leave only relevant blocks. These anchor blocks and object maps computed by the original CNN model correspond to the Fast R-CNN model.
Faster R-CNN uses RPN to avoid the selective search method, speed up the training and testing processes, and improve performance.
The You Only Look Once (YOLO) method is less accurate than regional convolutional neural networks, but it is much faster, allowing real-time object detection [5]. The essence of this method is to initially divide the image into a grid of cells. Each cell is responsible for the location of an object region in the image, if the centre of this region is within the cell. For each region, the x and y coordinates, the width and height of the region, and a confidence factor are determined, which indicates the probability that an object is present in that region. This confidence is simply the probability of detecting an object multiplied by the IoU (or intersection by union) between the predicted and actual values. The simplicity of the YOLO model allows real-time predictions to be made. The network has 24 convolutional layers followed by 2 fully connected layers (Figure 2).
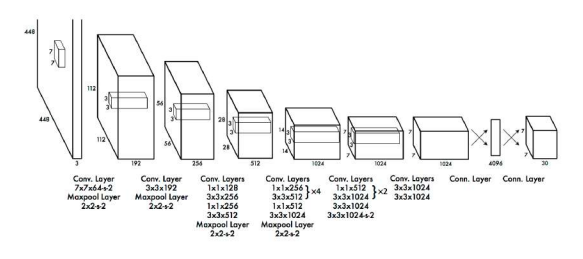
Figure 2. YOLO archicture
The basic principles of YOLO:
- Single-stage detection. YOLO solves the problem of object detection in a single network access. It is a one-stage architecture, which is in stark contrast to traditional two-stage methods such as R CNNs or Faster R CNNs, where candidate regions are first generated and then classified. The YOLO approach significantly speeds up image processing, making it ideal for real-time tasks.
- Fixed size grid. The image is divided into a grid where each cell is responsible for predicting the bounding boxes and the probabilities of the classes of objects within that cell [5]. This simplifies the processing of complex scenes with multiple objects.
- Prediction of bounding boxes. For each cell, YOLO predicts a fixed number of bounding boxes. Each box is described by the centre coordinates, width, height and probability of containing an object.
- Object classification. In addition to predicting frames, YOLO also determines the probability of an object belonging to a particular class. This allows us to identify which object is within each frame.
The advantages of the YOLO model include speed as the algorithm is able to recognise objects in real time, high accuracy, and the ability to generalise the image without burdening memory with processing. However, this algorithm has problems in identifying close objects.
Table 1.
Comparative analysis of R-CNN and YOLO class models
| Model | Advantages | Disadvantages | Application |
| R-CNN (Fast R-CNN, Faster R-CNN) | Highly accurate localisation of objects;
Flexibility to atypical objects and conditions; Increased efficiency with pre-trained models. |
Slow output and high computational load;
Not suitable in tasks involving video analysis; Difficult to train. |
Tumour detection;
Detection of objects on the road; Retail. |
| YOLO | High processing speed in tasks requiring instantaneous response;
Balance between precision and recall; Relatively simple architecture; Good at generalising common features. |
Has difficulty detecting small objects or objects that are far away;
Limited flexibility in customisation; Highly dependent on the variety of training data. |
Customer behaviour analysis;
CCTV systems; Tasks requiring rapid analysis and anomaly detection; Autonomous vehicles. |
This study found that the R-CNN and YOLO family models have different advantages and disadvantages that make them suitable for different applications. The R-CNN models exhibit higher object detection accuracy but require significant computational resources and are slower. In contrast, YOLO models provide high processing speed, which makes them attractive for real-time tasks, although their accuracy may be lower.
The choice between these two groups of models depends on the specific requirements of the project. If accuracy is a priority, R-CNN models should be favoured. If speed of processing is more important, then YOLO will be a better choice. It is important to note that both approaches continue to evolve and new versions of the models seek to combine the best features of both groups, providing both high accuracy and speed.
References
1. Верхов, К.А. Обнаружение объектов на изображении с использованием машинного обучения/ К.А. Верхов // Новые информационные технологии в научных исследованиях: материалы XXV Юбилейной Всероссийской научно-технической конференции студентов, молодых ученых и специалистов; Рязань: ИП Коняхин А.В. (Book Jet), 2020 – С. 226-227.2. Тропченко А.А., Тропченко А.Ю. Методы вторичной обработки и распознавания изображений. Учебное пособие. – СПб: Университет ИТМО,
2015. – 215 с.
3. Вапник В.Н. Червоненкис А.Я. Теория распознавания образов — М.: Издательство «Наука», 1974. — 416 с.
4. Николенко, С.И. Глубокое обучение. Погружение в мир нейронных сетей. / С.И. Николенко, А.А. Кудрин, Е.В. Архангельская – Санкт-Петербург : Питер, 2018. – 480 с.
5. The evolution of YOLO: Object detection algorithms [Электронный ресурс]. – Режим доступа: https://www.superannotate.com/blog/yolo-object-detection (Дата обращения: 27.02.2025).