Abstract: Statistical analysis is an integral part of modern biomedical research. However, the incorrect application of statistical methods can lead to erroneous conclusions and reduce the value of scientific work. This article discusses the most common errors in statistical analysis, such as pseudoreplication, ignoring the verification of parametric test assumptions (normality, homogeneity of variances), p-hacking, and confusion between correlation and causation. Recommendations for their prevention are presented to improve the reliability and reproducibility of scientific results.
Keywords: statistical analysis, errors, pseudoreplication, p-hacking, normality of distribution, correlation, causation.
Актуальность. Грамотное применение статистических методов – залог достоверности выводов в любой научной дисциплине, особенно в медицине и биологии. Несмотря на широкую доступность статистических пакетов, количество публикаций с методологическими ошибками в анализе данных остается высоким [1, 2]. Это приводит к публикации неверных результатов, искажению научной картины мира и, в конечном счете, может повлиять на клинические решения. Проведенные обзоры показывают, что такие ошибки, как псевдорепликация и некорректное использование значения p, встречаются в значительном проценте статей в ведущих рецензируемых журналах [3].
Цель исследования систематизировать типичные ошибки статистического анализа в научных статьях и предложить практические рекомендации по их предотвращению.
Материалы и методы исследования. Для выявления и анализа типичных ошибок был проведен систематический обзор отечественных и зарубежных публикаций по методологии статистического анализа в медико-биологических науках за период 2015-2024 гг. Акцент был сделан на работы, посвященные критике распространенных статистических практик и разработке руководств по надлежащему применению статистических методов.
Результаты.
- Псевдорепликация. Одна из наиболее частых и серьезных ошибок в биомедицинских исследованиях. Псевдорепликация возникает, когда за независимые наблюдения принимаются множественные измерения, полученные от одного и того же объекта (например, измерение показателя в нескольких точках одного органа у одного пациента), или, когда данные имеют иерархическую структуру (например, студенты в группах, клетки в чашках Петри), а анализ проводится без учета этой структуры [4]. Это искусственно завышает объем выборки (n) и увеличивает риск получения ложноположительных результатов (ошибка I рода).
Как избежать: Использовать методы, учитывающие кластерную или иерархическую природу данных: смешанные линейные модели (mixed models), обобщенные оценочные уравнения (GEE) или проводить анализ на уровне усредненных по объекту наблюдений.
- Игнорирование проверки предпосылок параметрических тестов. Параметрические тесты (такие как t-критерий Стьюдента, ANOVA) требуют соблюдения определенных условий: нормальность распределения данных и гомогенность (равенство) дисперсий в сравниваемых группах. Применение этих тестов без предварительной проверки предпосылок может сделать результаты некорректными.
Как избежать:
Нормальность: Проверять с помощью тестов (Шапиро-Уилка, Колмогорова-
Смирнова) и графических методов (Q-Q plot).
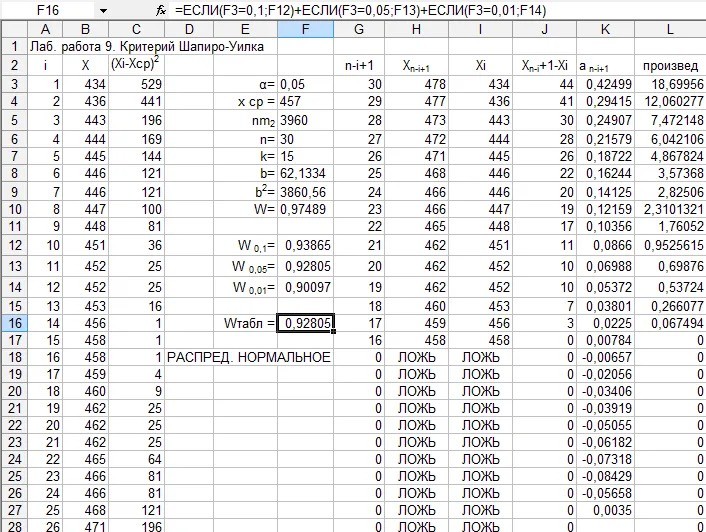
Рисунок 1. Проверка на нормальность распределения (Тест Шпиро-Уилка).
При нарушении нормальности использовать непараметрические аналоги (Манна-Уитни, Краскала-Уоллиса) или преобразования данных.
Гомогенность дисперсий: Проверять с помощью теста Левена или Бартлетта. При неоднородности дисперсий использовать модификации параметрических тестов (например, t-критерий Уэлча, поправку Уэлча в ANOVA).
- «P-hacking» (подбор данных до достижения значимости). Эта практика включает множественное проведение анализа с небольшими изменениями (исключение выбросов, добавление/удаление ковариат, различные способы группировки данных) до тех пор, пока не будет получено статистически значимое значение p < 0,05. Это приводит к ложному завышению числа значимых результатов [5].
Как избежать: Заранее планировать дизайн исследования и стратегию анализа в протоколе. Использовать поправки на множественные сравнения (Бонферрони, ФДР). Отчитываться обо всех проведенных анализах, а не только о значимых. Регистрировать исследование до начала сбора данных.
- Путаница между корреляцией и причинно-следственной связью. Обнаружение статистической связи между двумя переменными (корреляции) не означает, что одна переменная является причиной изменения другой. Наличие связи может быть обусловлено действием третьей, скрытой переменной (confounding factor) или простым
совпадением.
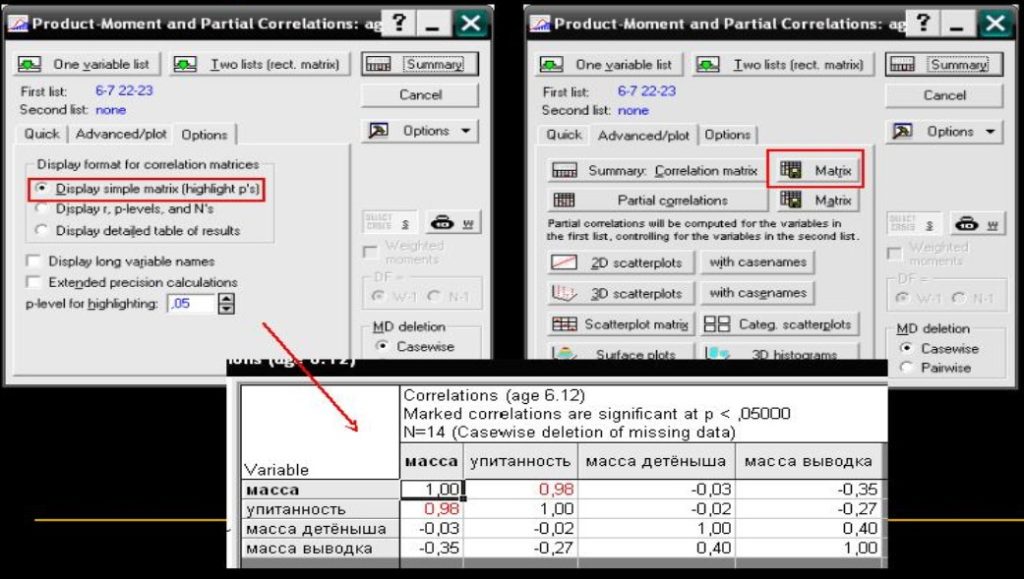
Рисунок 2. Пример путаницы между корреляцией и причинно-следственной связью.
Как избежать: Интерпретировать результаты корреляционного анализа с осторожностью. Для установления причинно-следственной связи необходимо планирование специальных исследований (рандомизированные, контролируемые испытания, лонгитюдные когортные исследования) и применение специальных методов анализа (инструментальные переменные, методы оценки склонностей. [2].
Заключение. Предотвращение распространенных статистических ошибок требует от исследователей повышения уровня методологической грамотности и строгого следования принципам планирования исследования и анализа данных. Соблюдение изложенных рекомендаций позволит повысить достоверность, надежность и воспроизводимость научных результатов в медико-биологических исследованиях, что является краеугольным камнем доказательной медицины.
References
1. Реброва О.Ю. Статистический анализ медицинских данных. Применение пакета прикладных программ STATISTICA. – 3-е изд. – М.: Медиа Сфера, 2022. – 312 с.2. Гржибовский А.М., Иванов С.В., Горбатова М.А. Анализ номинальных данных в научных исследованиях: от описательной статистики к логистической регрессии // Наука и Здравоохранение. – 2020. – Т. 22, № 5. – С. 5-16.
3. Гржибовский А.М. P-value: что это такое и как его правильно интерпретировать? // Экология человека. – 2021. – № 12. – С. 55-62.
4. Каприн А.Д., Куташов Е.А., Романов И.С. Методологические ошибки при планировании и статистической обработке данных в биомедицинских исследованиях // Бюллетень сибирской медицины. – 2023. – Т. 22, № 1. – С. 16-25.
5. Федоров А.С., Потапов А.В. Проблема p-hacking в научных публикациях и способы её решения // Вестник РГМУ. – 2022. – № 3. – С. 102-107.
6. Смирнов А.А., Орлова Д.И. Проблемы статистической обработки данных в современных медицинских исследованиях // Вестник РАМН. – 2022. – Т. 77, № 3. – С. 45-52.
7. Лебедева М.К., Воронцов А.С. Проблема p-hacking в российских научных публикациях: анализ и пути решения // Научные исследования и разработки. – 2023. – Т. 11, № 4. – С. 112-120.