Abstract: The architecture of a lossless hyperspectral data compressor prototype is considered. Static and block-adaptive variants of the encoder organization scheme are proposed. The principle of operation and the output file format are defined for the block-adaptive compressor. The compressor performance results on real data demonstrated a compression ratio close to the Shannon limit.
Keywords: hyperspectral data; lossless compression; tANS encoding; block‑adaptive compressor.
Гиперспектральные изображения характеризуются большим количеством спектральных каналов (сотни и тысячи) по сравнению с классическими RGB изображениями. По этой причине становится актуальной задача сжатия таких изображений. Изображение получается в результате работы прибора интерферометра, каждый его отсчет называют интерферограммой. Каждая интерферограмма представляет собой массив чисел, отвечающих за спектральные каналы в нем. Визуально один пиксель (интерферограмма) такого изображения показан на рисунке 1.
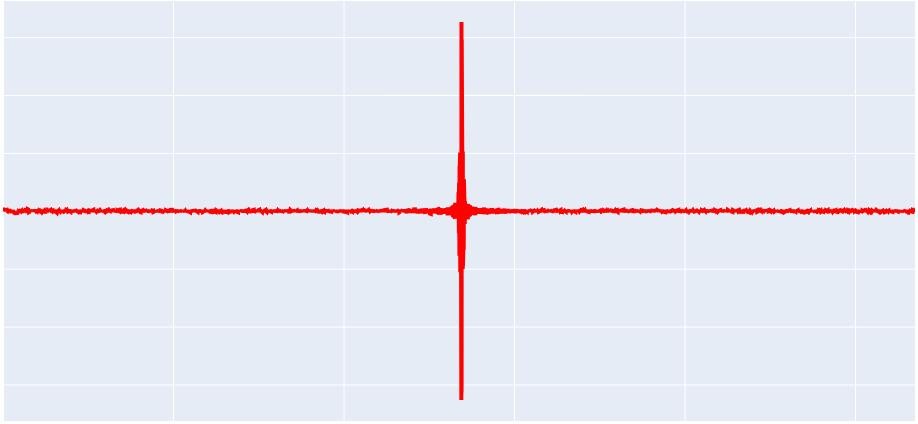
Рисунок 1. Графическое изображение одной интерферограммы
В имеющемся наборе данных, каждая интерферограмма состоит из 26000 отсчетов в формате S16_LE, то есть целое 16-битное число со знаком. Каждая интерферограмма имеет характерный всплеск значений примерно по середине каждого отсчета, а также шумоподобные области значений слева и справа от этого пика.
Для сжатия подобных отсчетов можно использовать энтропийные методы сжатия такие, как коды Хаффмана, арифметическое кодирование, или ANS методы [1]. Наиболее перспективным является использование ANS методов, поскольку они сочетают в себе эффективность арифметического кодирования вместе со скоростью работы кодов Хаффмана. При этом ANS методы строятся на основе целочисленной арифметики, благодаря чему могут быть использованы в том числе во встраиваемых системах [2].
В качестве энтропийного кодировщика будем использовать tANS компрессор. Выбор этого метода обусловлен тем, что в нем весь процесс кодирования описывается таблицей переходов состояний, которую можно составить один раз в начале работы, дальнейшее кодирование ограничено только скоростью доступа к памяти. Результат применения tANS метода без дополнительной обработки данных показан на рисунке 2.
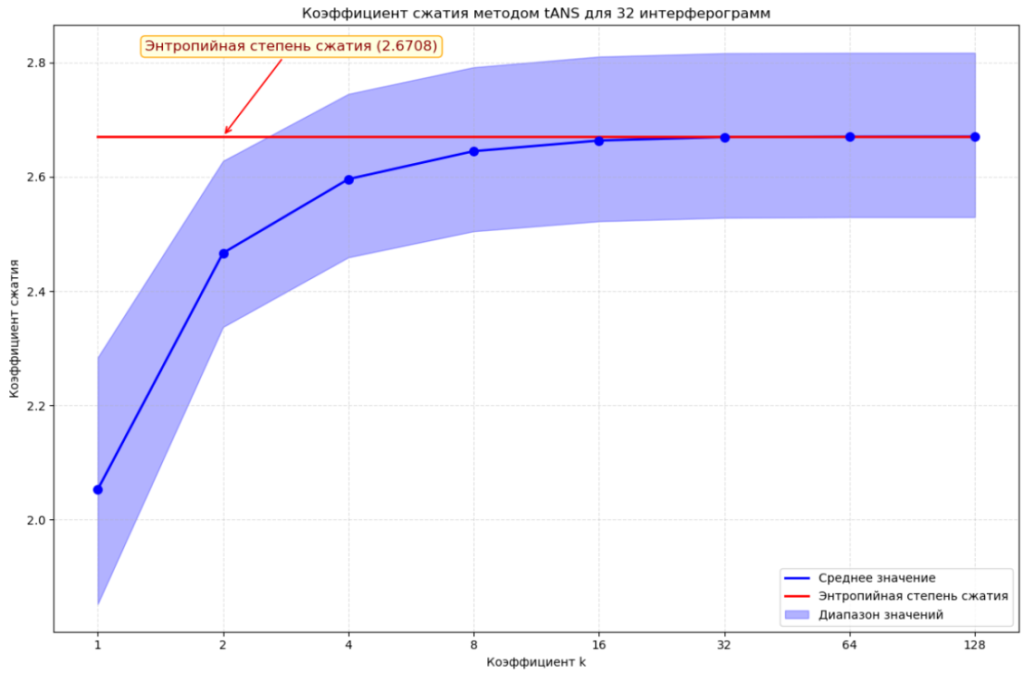
Рисунок 2. Сжатие методом tANS на исходных данных
Коэффициент k задает размер таблицы кодирования, кратный числу символов алфавита в нем. Красной линией показан энтропийный предел по Шеннону. Видно, что при k=8 метод показывает коэффициент сжатия, близкий к пределу. Однако в данном случае алфавит был индивидуальным для каждой интерферограммы, чего в общем случае допускать нельзя. В данном эксперименте в одном снимке встречалось 400-500 уникальных значений. Поскольку диапазон значений является , то размер базовой таблицы также должен быть равен . При ее размер кратно увеличится в раз [3], поэтому необходимо преобразование данных.
Заметим, что диапазон значений интерферограммы на рисунке 1 содержит большое количество околонулевых значений. Тогда можно разделить исходный поток с помощью метода разделения мантисс и экспонент на два потока: поток старших битов и поток младших битов. Для того чтобы обеспечить большое количество нулевых значений, можно применить зигзаг кодирование – это окажет положительное влияние на степень сжатия tANS методом впоследствии [4]. Последовательность обработки в таком случае показана на рисунке 3.

Рисунок 3. Схема обработки данных в компрессоре гиперспектральных изображений
Исходные целочисленные данные со знаком преобразуются с помощью зигзаг кодирования в беззнаковый тип. Далее происходит разделение потока на два с помощью метода разделения мантисс и экспонент (SEM). Получившиеся потоки отдельно сжимаются tANS компрессорами, а сжатый поток от каждого из них записывается в выходной поток.
Возможно две организации кодировщика: статическая и блочно-адаптивная. Статическая реализация требует двойного прохода по данным: первый раз для накопления статистики для tANS компрессоров, второй – для сжатия. Такой подход помимо этого требует выделение памяти под буфер размера входного изображения, по этой причине расходы по памяти высоки. Однако tANS компрессор в таком случае кодирует максимально эффективно засчет знания статистики распределения входных данных.
Блочно-адаптивная реализация предполагает итеративную обработку входной последовательности блоками определенного размера. В таком случае после чтения каждого блока происходит накопление статистики по текущему и предыдущему блоку (в начале статистика инициализируется некоторым заранее известным образом), кодирование блока, и чтение следующего блока до тех пор, пока не закончатся данные для кодирования. В таком случае есть следующие параметры кодировщика: k1,k2 – кратность таблиц для старших и младших потоков, bs – размер блока в отсчетах, r – граница разделения старших битов от младших. Формат файла показан на рисунке 4.
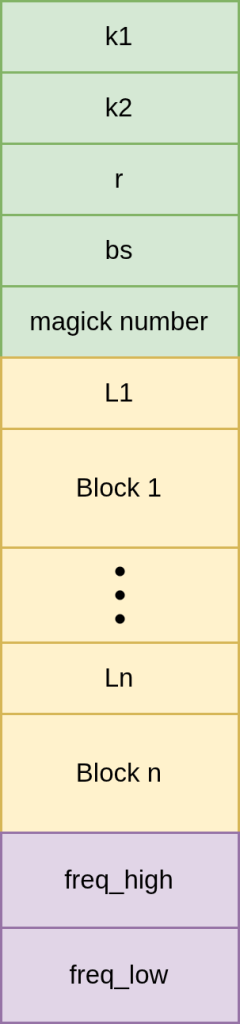
Рисунок 4. Структура сжатого файла кодировщиком гиперспектральных изображений
Для записи блока используется префиксная запись: сначала указывается его длина в битах, затем записывается поток закодированных битов.
Схема работы блочно-адаптивного компрессора показана на рисунке 5. По мере чтения входного потока, компрессор накапливает статистику по прочитанным символам. Исходный поток с помощью SEM метода, который реализует функция split_uint16_kbits, разделяется на два потока. Поток старших битов содержит r-битовые элементы, младших битов — 16−𝑟-битовые элементы. Отсюда следует, что в старших битах может встретиться различных значений, а в младших — . Поэтому зарезервируем массивы freq_high и freq_low таких размеров для подсчета статистики.
Далее компрессор выделяет память под хранение блока: high_block для старших битов, low_block — для младших, а также обновляется статистика обработанных символов в freq_high и freq_low. После чего выполняется итеративное чтение входного файла до тех пор, пока не будет достигнут конец файла. После прочтения каждого символа, увеличивается счетчик count, зигзаг кодирование отсчета и разделение его на старшие и младшие биты. Результат разделения записывается в два потока: high_block, low_block. Стоит отметить, что при 𝑟 = 8 элементы high_block и low_block являются 8-битными, в противном случае — 16-битными. При достижении счетчиком count значения bs, происходит кодирование очередного блока данных. Для этого вызывается функция do_encode. После завершения чтения файла, в буфере могут остаться данные, которые еще не были закодированы, поэтому в конце так же вызывается do_encode сначала для кодирования старших битов high_block, затем – младших битов low_block.
Функция do_encode выполняет кодирование блока данных. Сумма частот статистики символов масштабируется до 𝑘1 · 2𝑟 для старших битов и до 𝑘2 · 216−𝑟 для младших битов. После чего создается и инициализируется структура кодировщика. Результат работы кодировщика записывается в динамический массив. После обработки блока, вычисляется длина в битах закодированной последовательности. Длина блока записывается в выходной файл, после него записывается сама закодированная последовательность. Если число закодированных бит не кратно байтам, то используется дополнение незначащими нулями до целого числа байт.
По результатам тестирования, прототип блочно-адаптивного компрессора показал степень среднюю сжатия для набора из 32 интерферограмм на уровне 2.45 при k1=k2=8 и размере блока 1024 отсчетов. При увеличении k и размера блоков можно достичь степень сжатия, получаемой статическим вариантом компрессора, однако расходы памяти кратно увеличатся.
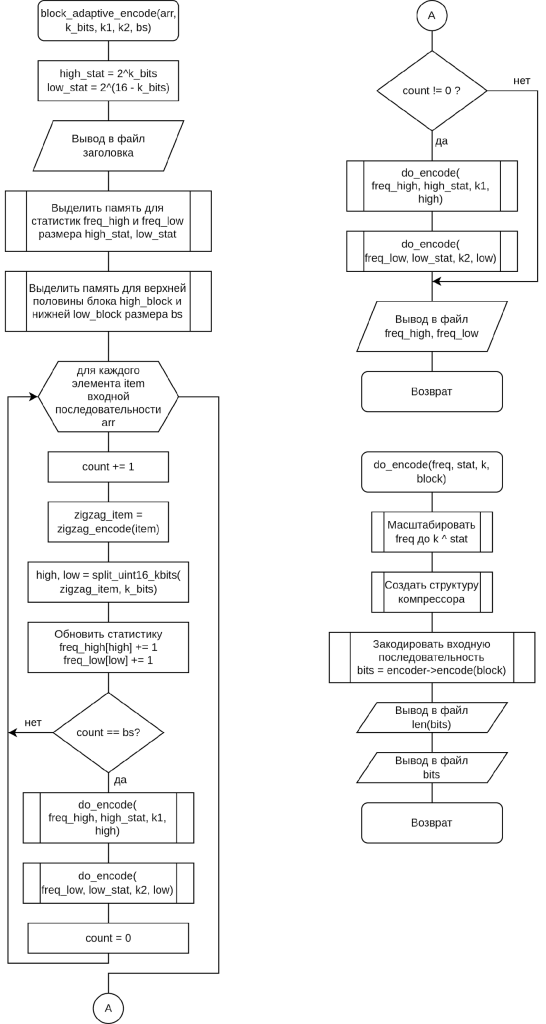
Рисунок 5. Схема работы блочно-адаптивного компрессора
References
1. Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео. – М.ДИАЛОГ-МИФИ, 2003. – С. 383.2. Tatwawadi K. What is Asymmetric Numeral Systems? [Электронный ресурс]. — 2019. — URL: https://kedartatwawadi.github.io/post--ANS/ (дата обращения 28.10.2025).
3. Duda J. Asymmetric numeral systems: entropy coding combining speed of Huffman coding with compression rate of arithmetic coding // arXiv preprint arXiv:1311.2540. — 2013.
4. Yamamoto H. Encoding and Decoding Algorithms of ANS Variants and Evaluation of Their Average Code Lengths // arXiv preprint arXiv:2408.07322. – 2024.